《这就是ChatGPT》是由传奇人物 史蒂芬·沃尔弗拉姆 写就,我曾经在多个地方听到过这位奇人的名字,比如说对元胞自动机的深入研究者,1000多页巨著《一种新科学》的作者。
通过此书,我才了解到此人在15岁时就可以在高能物理领域发表论文,论文还被多次引用,他还是知识计算引擎Wolfram|Alpha的作者,用户可以用自然语言向这个引擎提出问题,而系统通过将问题转化为 Wolfram 语言,这种 Wolfram 可以根据事物本身的联系进行逻辑推导,得出相当惊人且准确的答案。
他被誉为“世界上最聪明的人”,而这本书,就是他用非常浅显的语言介绍了chatGPT的工作原理,并基于GPT的工作原理,给出了他对人类自然语言的思考。
在文章的最后,他也讨论了chatGPT与他的Wolfram语言的差异,以及结合工作的可能。
以下是读书笔记
首先需要解释,ChatGPT从根本上始终要做的是,针对它得到的任何文本产生“合理的延续”。 这里所说的“合理”是指,“人们在看到诸如数十亿个网页上的内容后,可能期待别人会这样写”。
如何用神经网络实现这一点呢? 归根结底,神经网络是由理想化的“神经元”组成的连接集合—通常是按层排列的。 一个简单的例子如下所示。
每个“神经元”都被有效地设置为计算一个简单的数值函数。 为了“使用”这个网络,我们只需在顶部输入一些数(像我们的坐标x和y),然后让每层神经元“计算它们的函数的值”并在网络中将结果前馈,最后在 底部产生最终结果。
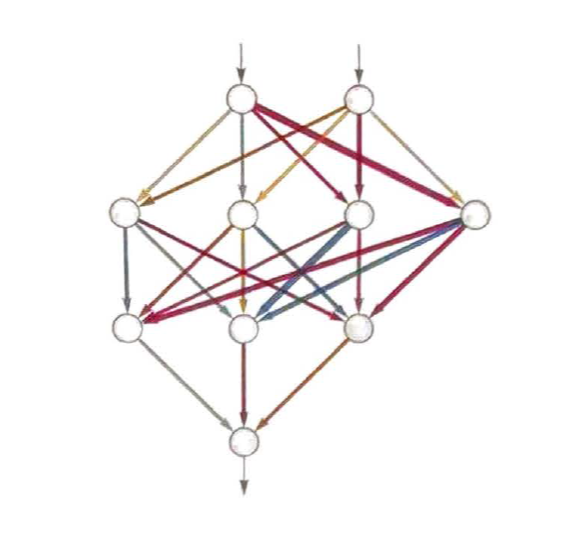
在传统(受生物学启发)的设置中,每个神经元实际上都有一些来自前一层神经元的“输入连接”,而且每个连接都被分配了一个特定的“权重”(可以为正 或为负)。 给定神经元的值是这样确定的:先分别将其“前一层神经元”的值乘以相应的权重并将结果相加,然后加上一个常数,最后应用一个“阈值”(或“激活 ”)函数。 用数学术语来说,如果一个神经元有输入x={x1,x2,···},那么我们要计算f[w·x+b]。 对于权重w和常量b,通常会为网络中的每个
神经元选择不同的值;函数f则通常在所有神经元中保持不变。
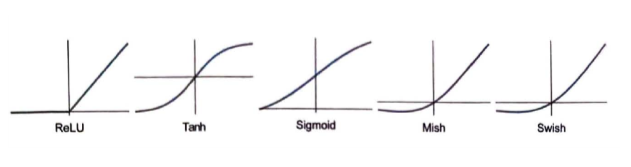
计算w·x+b只需要进行矩阵乘法和矩阵加法运算。 激活函数f则使用了非线性函数(最终会导致非平凡的行为)。 下面是一些常用的激活函数,这里使用的是Ramp(或ReLU)。
到目前为止,我们没办法对网络正在做什么“给出语言描述”。 也许这是因为它确实是计算不可约的,除了明确跟踪每一步之外,没有可以找出它做了什么的一般方法。 也有可能只是因为我们还没有“弄懂科学”,也没有发现能总结正在发生的事情的“自然法则”。
当ChatGPT做一些事情,比如写一篇文章时,它实质上只是在一遍又一遍地询问“根据目前的文本,下一个词应该是什么”,并且每次都添加一个词。 正如我将要解释的那样,更准确地说,它是每次都添加一个“标记”(token),而标记可能只是词的一部分。 这就是它有时可以“造词”的原因。
在每一步都会得到一个带概率的词列表。 但它应该选择将哪一个词添加到正在写作的文章中呢? 有人可能认为应该选择“排名最高”的词,即分配了最高“概率”的词。 然而,这里出现了一点儿玄学的意味。 出于某种原因—也许有一天能用科学解释—如果我们总是选择排名最高的词,通常会得到一篇非常“平淡”的文章,完全显示不出任何“创造力”(有时甚至会 一字不差地重复前文)。 但是,如果有时(随机)选择排名较低的词,就会得到一篇“更有趣”的文章。
而且,符合玄学思想的是,有一个所谓的“温度”参数来确定低排名词的使用频率。 对于文章生成来说,“温度”为0.8似乎最好。 (值得强调的是,这里没有使用任何“理论”,“温度”参数只是在实践中被发现有效的一种方法。例如,之所以采用“温度”的概念,是因为碰巧使用了在统计物理学中 很常见的某种指数分布,但它与物理学之间并没有任何实际联系,至少就我们目前所知是这样的。)
为了明白离目标“有多远”,我们计算“损失函数”(有时也称为“成本函数”)。 这里使用了一个简单的(L2)损失函数,就是我们得到的值与真实值之间的差异的平方和。 随着训练过程不断进行,我们看到损失函数逐渐减小(遵循特定的“学习曲线”,不同任务的学习曲线不同),直到神经网络成功地复现(或者至少很好地近似)我们想要 的函数。
有时候用神经网络解决复杂问题比解决简单问题更容易—这似乎有些违反直觉。 大致原因在于,当有很多“权重变量”时,高维空间中有“很多不同的方向”可以引导我们到达最小值;而当变量较少时,很容易陷入局部最小值的“山湖”, 无法找到“出去的方向”。
在神经网络的早期发展阶段,人们倾向于认为应该“让神经网络做尽可能少的事”。 例如,在将语音转换为文本时,人们认为应该先分析语音的音频,再将其分解为音素,等等。 但是后来发现,(至少对于“类人任务”)最好的方法通常是尝试训练神经网络来“解决端到端的问题”,让它自己“发现”必要的中间特征、编码等。 还有一种想法是,应该将复杂的独立组件引入神经网络,以便让它有效地“显式实现特定的算法思想”。 但结果再次证明,这在大多数情况下并不值得;相反,最好只处理非常简单的组件,并让它们“自我组织”(尽管通常是以我们无法理解的方式)来实现(可能)等 效的算法思想。
还有一种想法是,应该将复杂的独立组件引入神经网络,以便让它有效地“显式实现特定的算法思想”。 但结果再次证明,这在大多数情况下并不值得;相反,最好只处理非常简单的组件,并让它们“自我组织”(尽管通常是以我们无法理解的方式)来实现(可能)等 效的算法思想。
 但是,如何确定特定的任务需要多大的神经网络呢? 这有点像一门艺术。 在某种程度上,关键是要知道“任务有多难”。 但是类人任务的难度通常很难估计。 是的,可能有一种系统化的方法可以通过计算机来非常“机械”地完成任务,但是很难知道是否有一些技巧或捷径有助于更轻松地以“类人水平”完成任务。 可能需要枚举一棵巨大的对策树才能“机械”地玩某个游戏,但也可能有一种更简单的(“启发式”)方法来实现“类人的游戏水平”。
但是,如何确定特定的任务需要多大的神经网络呢? 这有点像一门艺术。 在某种程度上,关键是要知道“任务有多难”。 但是类人任务的难度通常很难估计。 是的,可能有一种系统化的方法可以通过计算机来非常“机械”地完成任务,但是很难知道是否有一些技巧或捷径有助于更轻松地以“类人水平”完成任务。 可能需要枚举一棵巨大的对策树才能“机械”地玩某个游戏,但也可能有一种更简单的(“启发式”)方法来实现“类人的游戏水平”。
那么ChatGPT呢? 它有一个很好的特点,就是可以进行“无监督学习”,这样更容易获取训练样例。 回想一下,ChatGPT的基本任务是弄清楚如何续写一段给定的文本。 因此,要获得“训练样例”,要做的就是取一段文本,并将结尾遮盖起来,然后将其用作“训练的输入”,而“输出”则是未被遮盖的完整文本。 我们稍后会更详细地讨论这个问题,这里的重点是—(与学习图像内容不同)不需要“明确的标签”,ChatGPT实际上可以直接从它得到的任何文本样例中学习。
换句话说,能力和可训练性之间存在着一个终极权衡:你越想让一个系统“真正利用”其计算能力,它就越会表现出计算不可约性,从而越不容易被训练;而 它在本质上越易于训练,就越不能进行复杂的计算。
这并不是正确的结论。 计算不可约过程仍然是计算不可约的,对于计算机来说仍然很困难,即使计算机可以轻松计算其中的每一步。 我们应该得出的结论是,(像写文章这样)人类可以做到但认为计算机无法做到的任务,在某种意义上计算起来实际上比我们想像的更容易
如果有一个足够大的神经网络,那么你可能能够做到人类可以轻易做到的任何事情。 但是你无法捕捉自然界一般而言可以做到的事情,或者我们用自然界塑造的工具可以做到的事情。 而正是这些工具的使用,无论是实用性的还是概念性的,近几个世纪以来使我们超越了“纯粹的无辅助的人类思维”的界限,为人类获取了物理宇宙和计算宇宙之外 的很多东西。
[严格来说,ChatGPT并不处理词,而是处理“标记”(token)—这是一种方便的语言单位,既可以是整个词,也可以只是像pre、ing或ized这样的片段。 使用标记使ChatGPT更容易处理罕见词、复合词和非英语词,并且会发明新单词(不论结果好坏)。 ]
我们终于准备好讨论ChatGPT的内部原理了。 从根本上说,ChatGPT是一个庞大的神经网络—GPT—3拥有1750亿个权重。 它在许多方面非常像我们讨论过的其他神经网络,只不过是一个特别为处理语言而设置的神经网络。 它最显著的特点是一个称为Transformer的神经网络架构。
在前面讨论的神经网络中,任何给定层的每个神经元基本上都与上一层的每个神经元相连(起码有一些权重)。 但是,如果处理的数据具有特定的已知结构,则这种全连接网络就(可能)大材小用了。 因此,以图像处理的早期阶段为例,通常使用所谓的卷积神经网络(convolutional neural net或convnet),其中的神经元被有效地布局在类似于图像像素的网格上,并且仅与 在网格上相邻的神经元相连。
Transformer的思想是,为组成一段文本的标记序列做与此相似的事情。 但是,Transformer不是仅仅定义了序列中可以连接的固定区域,而是引入了“注意力”的概念—即更多地“关注”序列的某些部分,而不是其他部分。 也许在将来的某一天,可以启动一个通用神经网络并通过训练来完成所有的定制工作。 但至少目前来看,在实践中将事物“模块化”似乎是至关重要的—就像Transformer所做的那样,也可能是我们的大脑所做的那样。
它的操作分为三个基本阶段。 第一阶段,它获取与目前的文本相对应的标记序列,并找到表示这些标记的一个嵌入(即由数组成的数组)。 第二阶段,它以“标准的神经网络的方式”对此嵌入进行操作,值“像涟漪一样依次通过”网络中的各层,从而产生一个新的嵌入(即一个新的数组)。 第三阶段,它获取此数组的最后一部分,并据此生成包含约50000个值的数组,这些值就成了各个可能的下一个标记的概率。 (没错,使用的标记数量恰好与英语常用词的数量相当,尽管其中只有约3000个标记是完整的词,其余的则是片段。)
关键是,这条流水线的每个部分都由一个神经网络实现,其权重是通过对神经网络进行端到端的训练确定的。 换句话说,除了整体架构,实际上没有任何细节是有“明确设计”的,一切都是从训练数据中“学习”来的。
为什么只是将标记值和标记位置的嵌入向量相加呢? 我不认为有什么特别的科学依据。 只是因为尝试了各种不同的方法,而这种方法似乎行得通。 此外,神经网络的学问告诉我们,(在某种意义上)只要我们的设置“大致正确”,通常就可以通过足够的训练来确定细节,而不需要真正“在工程层面上理解”神经网络是 如何配置自己的。
在嵌入模块之后,就是Transformer的“主要事件”了:一系列所谓的“注意力块”(GPT-2有12个,ChatGPT的GPT-3有96个)。 整个过程非常复杂,让人想起难以理解的大型工程系统或者生物系统。 以下是(GPT—2中)单个“注意力块”的示意图。
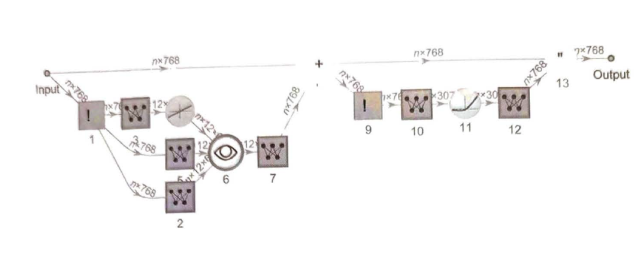 在每个这样的注意力块中,都有一组“注意力头”(GPT—2有12个,ChatGPT的GPT—3有96个)—每个都独立地在嵌入向量的不同值块上进行 操作。 (我们不知道为什么最好将嵌入向量分成不同的部分,也不知道不同的部分“意味”着什么。这只是那些“被发现奏效”的事情之一。)
在每个这样的注意力块中,都有一组“注意力头”(GPT—2有12个,ChatGPT的GPT—3有96个)—每个都独立地在嵌入向量的不同值块上进行 操作。 (我们不知道为什么最好将嵌入向量分成不同的部分,也不知道不同的部分“意味”着什么。这只是那些“被发现奏效”的事情之一。)
注意力头是做什么的呢? 它们基本上是一种在标记序列(即目前已经生成的文本)中进行“回顾”的方式,能以一种有用的形式“打包过去的内容”,以便找到下一个标记。 在“概率从何而来”一节中,我们介绍了使用二元词的概率来根据上一个词选择下一个词。 Transformer中的“注意力”机制所做的是允许“关注”更早的词,因此可能捕捉到(例如)动词可以如何被联系到出现在句子中很多词之前的名词。
值得注意的是,所有这些操作—尽管各自都很简单—可以一起出色地完成生成文本的“类人”工作。 必须再次强调,(至少就我们目前所知)没有“理论上的终极原因”可以解释为什么类似于这样的东西能够起作用。 事实上,正如我们将讨论的那样,我认为必须将其视为一项(可能非常惊人的)科学发现:在像ChatGPT这样的神经网络中,能以某种方式捕捉到人类大脑在生成语言时 所做事情的本质。
我们已经概述了ChatGPT在设置后的工作方式。 但是它是如何设置的呢? 那1750亿个神经元的权重是如何确定的呢? 基本上,这是基于包含人类所写文本的巨型语料库(来自互联网、书籍等),通过大规模训练得出的结果。 正如我们所说,即使有所有这些训练数据,也不能肯定神经网络能够成功地产生“类人”文本。 似乎需要细致的工程设计才能实现这一点。 但是,ChatGPT带来的一大惊喜和发现是,它完全可以做到。 实际上,“只有1750亿个权重”的神经网络就可以构建出人类所写文本的一个“合理模型”。
ChatGPT内部并没有直接存储来自互联网、书籍等的所有文本。 因为ChatGPT内部实际上是一堆数(精度不到10位),它们是所有文本的总体结构的某种分布式编码。
当我们运行ChatGPT来生成文本时,基本上每个权重都需要使用一次。 因此,如果有n个权重,就需要执行约n个计算步骤—尽管在实践中,许多计算步骤通常可以在GPU中并行执行。 但是,如果需要约n个词的训练数据来设置这些权重,那么如上所述,我们可以得出结论:需要约n2个计算步骤来进行网络的训练。 这就是为什么使用当前的方法最终需要耗费数十亿美元来进行训练。
那么,ChatGPT是如何在语言方面获得如此巨大成功的呢? 我认为基本答案是,语言在根本上比它看起来更简单。 这意味着,即使是具有简单的神经网络结构的ChatGPT,也能够成功地捕捉人类语言的“本质”和背后的思维方式。 此外,在训练过程中,ChatGPT已经通过某种方式“隐含地发现”了使这一切成为可能的语言(和思维)规律。
在一定长度内,网络是可以正常工作的。 但是一旦超出这个长度,它就开始出错。 这是在神经网络(或广义的机器学习)等“精确”情况下经常出现的典型问题。 对于人类“一眼就能解决”的问题,神经网络也可以解决。 但对于需要执行“更算法式”操作的问题(例如明确计算括号是否闭合),神经网络往往会“计算过浅”,难以可靠地解决。 顺便说一句,即使是当前完整的ChatGPT在长序列中也很难正确地匹配括号。
但结果从来不是“完美”的。 也许有的东西能够在95%的时间内运作良好。 但是不论怎样努力,它的表现在剩下的5%时间内仍然难以捉摸。 对于某些情况来说,这可能被视为失败。 但关键在于,在各种重要的用例中,95%往往就“足够好了”。 原因也许是输出是一种没有“正确答案”的东西,也许是人们只是在试图挖掘一些可能性供人类(或系统算法)选择或改进。
人类不会受限于技术的演变,只会受限于自身设定的目标。